Brainstorm: "Automatiske klynger"
! Denne post er under konstant redigering. Der advares om at der forefindes grov misbrug af ord udenfor kontekst, og i forkert betydning - som meget muligt vil få enhver på Danmarks Biblioteksskole til at krænge tæer.
"Automatiske klynger"
Denne tekst er tænkt som en del-konklussion til en evt. opgave, dvs. et del-område, der muligvis kan inkluderes. Evt. bruges til at komme med en pointe i min endelige opgave. Referencer, citater og andet er ikke vedlagt.
Jeg har i noget tid, baseret på begrebet "link-clusters", tænkt på hvorvidt det måtte være muligt at lave noget lignende med tags - dvs. tags-clusters. Grundideen er forholdsvis simpel, et tag (T2) peger en mængde sider (M1) og et andet tag (T2) peger på en anden mængde sider (M2). Hvis fællesmængdes af M1 og M2 overstiger en hvis procentdel af enten M1 eller M2, vil disse to tags være relateret. Det er et forsøg der som sådan vil kunne udføres på del.icio.us og blogger uden de helt store problemer. Jeg forestiller mig følgende illustration: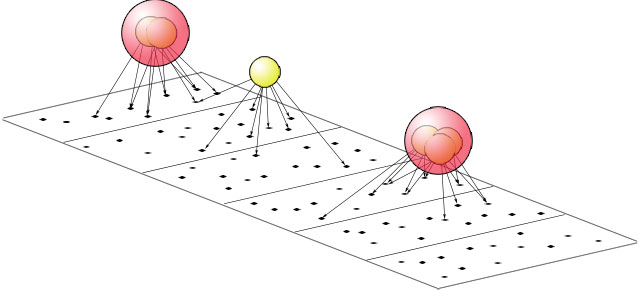 Ovenstående ser vi en falde (det kan være to del.icio.us profiler's der er "slået sammen"), samt seks tags. Tags er gule, links prikker, pilene betyder at et tag er "hæftet" på et link, og de røde bobler viser hvor der er en sandsynlighed for at vi faktisk har med det samme begreb at gøre. Reelt set, kan vi have at gøre med forskellen mellem ordene "Bibliotek" og "Biblioteker", men også "Bibliotek" og "Library". Vi burde altså, ud fra hvilke tags der er blevet giver til et bestemt link, kunne automatisk lave en form for "begrebsklynger".
Ovenstående ser vi en falde (det kan være to del.icio.us profiler's der er "slået sammen"), samt seks tags. Tags er gule, links prikker, pilene betyder at et tag er "hæftet" på et link, og de røde bobler viser hvor der er en sandsynlighed for at vi faktisk har med det samme begreb at gøre. Reelt set, kan vi have at gøre med forskellen mellem ordene "Bibliotek" og "Biblioteker", men også "Bibliotek" og "Library". Vi burde altså, ud fra hvilke tags der er blevet giver til et bestemt link, kunne automatisk lave en form for "begrebsklynger".
Ved et nærbillede af en begrebsklynge, kan man se hvordan de tre tags inde i klyngen, deler mange sider imellem sig: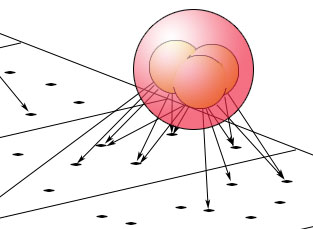
Det interessante ved hele denne tilgang til klynger er, at man tager udgangspunkt i tags og ikke i links.
![]()

Ingen kommentarer:
Send en kommentar